The LCRC operated Fusion, a 30 teraflop computing cluster from 2010 to early 2017. Fusion featured 320 publicly usable compute nodes with Nehalem 2.6 GHz Xeon processors and a Mellanox QDR InfiniBand fat tree network. Overall, Fusion was comprised of 360 compute nodes of varying architectures including private condo nodes. In its last few years of operation, Fusion was used for overflow from Blues and for industry partnership projects. Fusion was retired on January 31, 2017.
Quick Facts
- 320 public compute nodes
- 36 GB of memory on each node
- 200 GB of local scratch space
- 8 cores per compute node
- Mellanox QDR InfiniBand interconnect (fat-tree topology)
Available Queues
Fusion had several public queues to choose from. This does not list information on the private condo nodes. Below you can find some details on the types of nodes in each public queue.
| Fusion Cluster Queues | Nodes | Cores | Memory | Processor | Co-processors |
|---|---|---|---|---|---|
| shared | 4 | 8 | 64 GB | Xeon X5650 2.66 GHz | – |
| batch | 296 | 8 | 32 GB | Xeon X5650 2.66 GHz | – |
| gpu | 6 | 8 | 64 GB | Xeon E5-2650 2.0 GHz | 2x NVIDIA Tesla M2090 GPU |
File Storage
Please see our detailed description of the file storage used in LCRC here.
Architecture
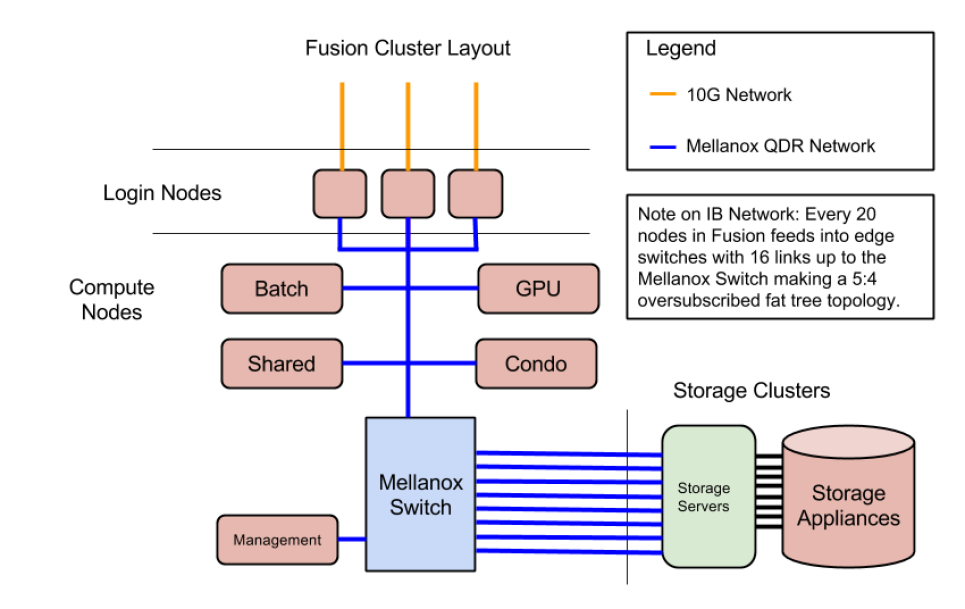
Fusion Network Diagram
For more detailed information on Fusion, please see the Fusion Briefing Document.
Industry Partnerships with Fusion
Fusion’s mission was focused on Argonne partnerships with industry, projects performed with the participation of industry staff or with deliverables to specific companies.